Lexing
Before your source code can be executed, the compiler or interpreter must first understand what you wrote in your program. This understanding is broken into two stages: lexing and parsing. The code that lexes is a lexer, and the code that parses is a parser.
The lexer's job is to read through the source code and collect the individual characters up into tokens. When you read text, you don't process individual characters. You chunk them into words. That chunking into words is the job of the lexer. In fact, the name lexer comes from the Greek word lexis, which means word. A token is sometimes called a lexeme, which is a term linguists use to describe the basic unit of language.
Lexing is a superficial task. If a lexer sees the letters ++i, it stops at producing the tokens ++ and i. It doesn't try to make any sense of the tokens. Identifying the semantic meaning of syntactic forms is the job of the parser.
Programs are made up of several different kinds of tokens. Keyword tokens are words that have special meaning in the language, like for, while, class, true, and return. Identifier tokens are names for variables, methods, classes, and labels. Literal tokens are raw data like 1929, 3.14159f, '?', and "seethe". Operator tokens are symbols like +, ==, !, and &. Common separators include , and ;. In many languages, four different kinds of enclosing brackets are found: [], (), <>, and {}. Languages diverge widely on their choice of comment tokens. Single-line comments start with the tokens //, #, --, or ;. Multi-line comments are surrounded by the token pairs /* and */, #| and |#, {- and -}, or =begin and =end.
Whitespace is often discarded. It is used to separate tokens but is not itself included in any tokens unless it's part of a string literal.
Integer Literals
Lexing by hand is a fun exercise, but we need to get a computer to do it for us. To recognize a particular kind of token, like identifiers or string literals, we build a little recognizing machine. That machine will ultimately be written in code, but let's first think about how it works using a picture—in particular, a state diagram. Here's the state diagram of a machine for recognizing integer literals:
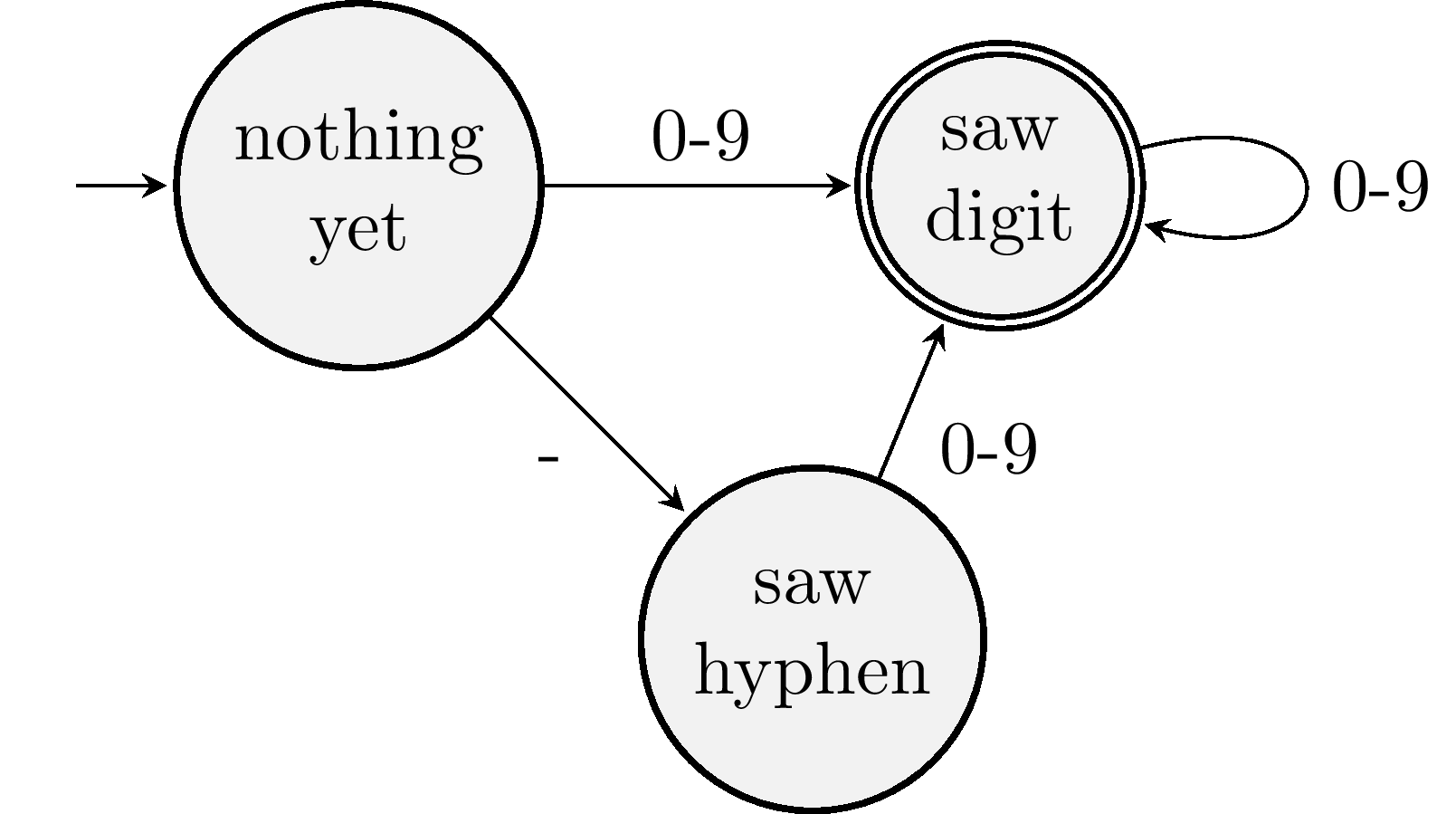
The diagram shows that this machine will be in one of three states. The arrows show how we move between states when we encounter a particular character. The unrooted arrow indicates that we start in the nothing yet state. At this point, we haven't read any of the characters in the source code. If we see a digit, we move to the saw digit state. If we see more digits, we stay in that state. Alternatively, suppose we see a hyphen first. Then we'd go into the saw hyphen state. If we then see a digit, we'd find ourselves in the saw digit state.
If we run out of characters or if we encounter a character for which there isn't a transition from our current state, we stop reading. If our current state is an accepting state, then we have found ourselves a legal token. Accepting states are marked with a double outline.
If we're not in an accepting state, then we either need to move to a different recognizing machine or we have bad source code and must issue an error. For example, if the source is -@, we read the -, land in saw hyphen, and cannot transition on @. We're not in an accepting state, so we reject this text as it's not an integer literal. On the other hand, if the source is 62 * 37, we read the digits 62, land in saw digits, and cannot transition on the space. We're in an accepting state, so we record the integer literal token and then try lexing another token from the remaining input * 37.
Now that we've explored the state diagram, let's consider how we might translate it to lexing code. Suppose our lexer has state for the source code, the token currently being lexed, and a list of tokens accepted so far. Its has and hasDigit methods compare the current character in the source against some pattern. Its capture method appends the current character from the source to the current token. The emitToken method appends the current token to the list of accepted tokens. Then we might express our machine with code like this:
if (has('-')) {
capture();
}
if (hasDigit()) {
while (hasDigit()) {
capture();
}
emitToken('integer-literal');
} else {
throw new Error('invalid integer literal');
}if (has('-')) {
capture();
}
if (hasDigit()) {
while (hasDigit()) {
capture();
}
emitToken('integer-literal');
} else {
throw new Error('invalid integer literal');
}This code allows but does not require an initial hyphen. It requires at least one digit but allows for more.
Identifiers
What would a machine for recognizing identifiers look like? In many languages, identifiers must start with a letter or an underscore. Subsequent symbols can be letters, numbers, or underscores. Here's a machine that recognizes identifiers that follow these rules:
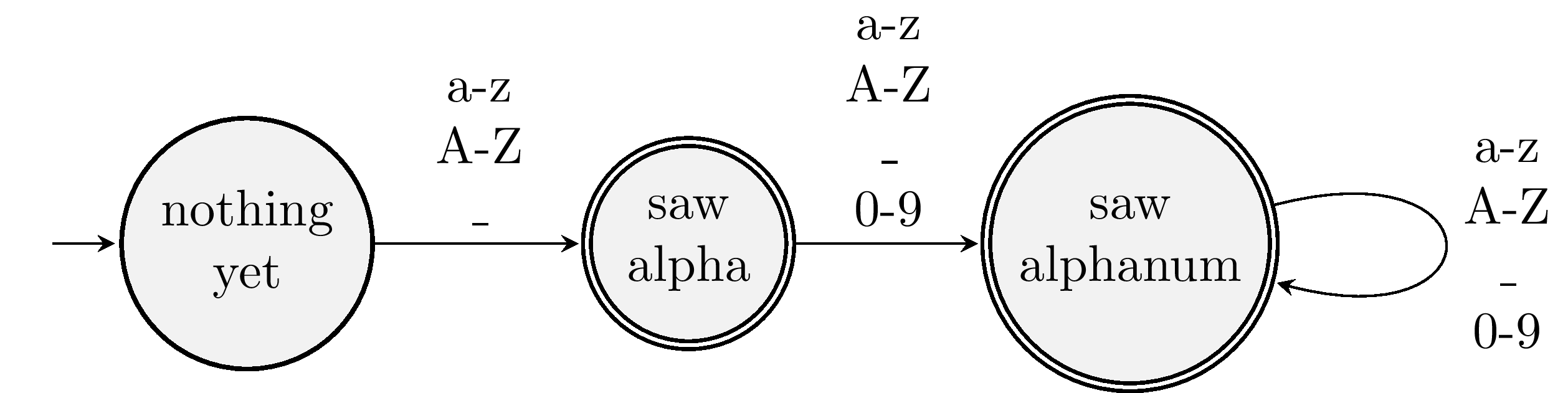
Could we have drawn this machine with fewer states?
Single-letter identifiers like i will drop us off in saw alpha. These are valid identifiers, so we make this an accepting state. Having more than one accepting state is legal. Suppose we run this machine on ii. We are in an accepting state after the first i, so we could stop there. But if we read the second i, we also land in an accepting state. Recognizing ii seems like a better idea. In fact, there's a generally accepted rule of programming languages that states that lexers will consume as much of the source code that they can when recognizing token. This greedy practice is called maximal munch.
The state diagram for identifiers may be translated into the following lexing code:
if (hasAlphabetic()) {
capture();
while (hasAlphanumeric()) {
capture();
}
emitToken('identifier');
}if (hasAlphabetic()) {
capture();
while (hasAlphanumeric()) {
capture();
}
emitToken('identifier');
}In general, we choose how to transition to the next state with a conditional statement. If that transition takes us back to an earlier state, we use a loop.
String Literals
What would a machine for recognizing string literals look like? String literals begin and end with a double quotation mark. Nearly any character can appear between these marks—even another double quotation mark. How does the lexer distinguish between an internal quotation mark and a delimiter? Many programming languages allow programmers to cancel the special meaning of a character by escaping it—often by preceding the character with a backslash. We add an extra state to our machine to handle backslash-escaped characters:
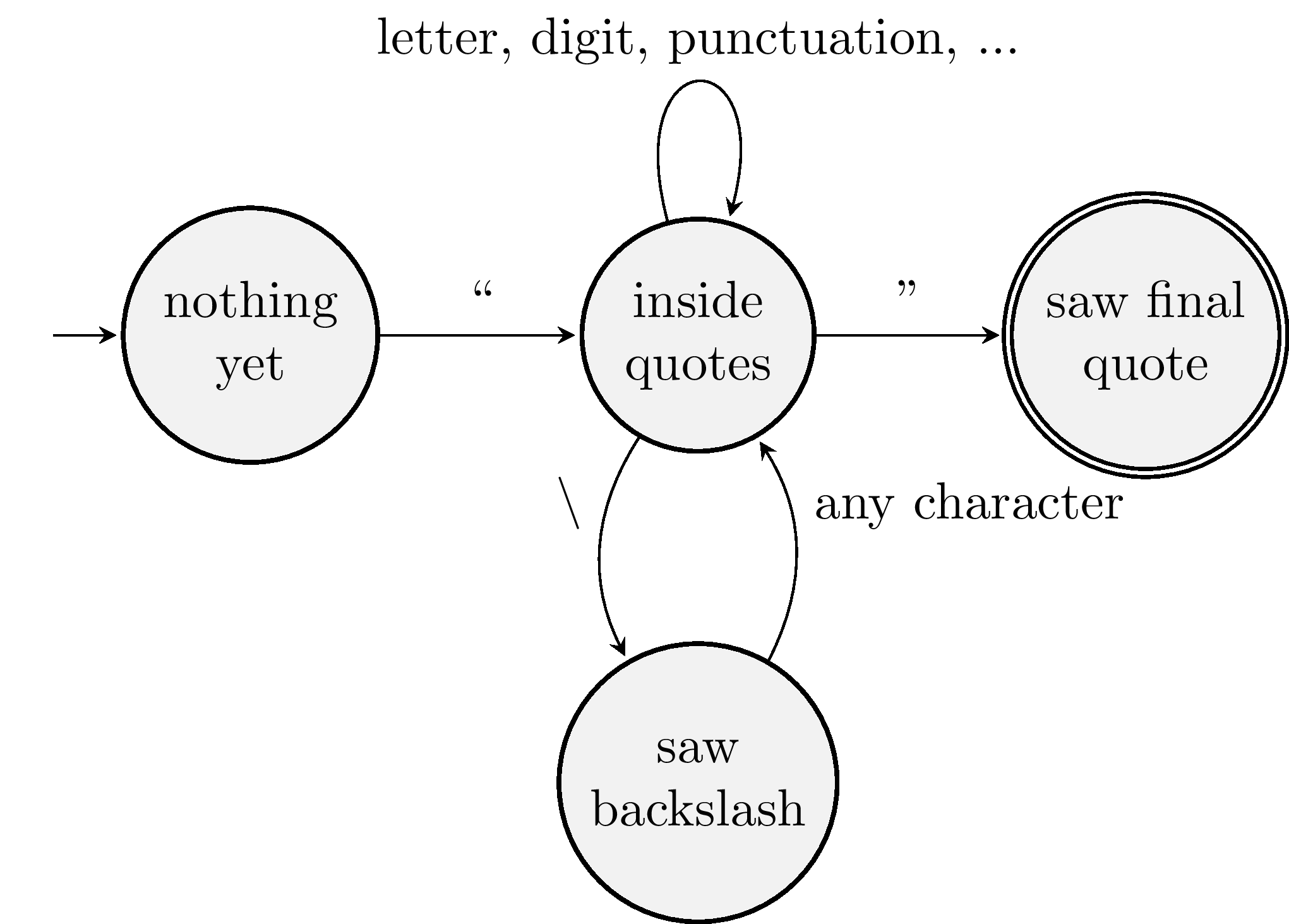
This machine might look like this lexing code:
if (has('"')) {
skip();
while (hasOtherwise('"')) {
if (has('\\')) {
skip();
}
capture();
}
if (has('"')) {
skip();
emitToken('string-literal');
} else {
throw 'unclosed string literal';
}
}if (has('"')) {
skip();
while (hasOtherwise('"')) {
if (has('\\')) {
skip();
}
capture();
}
if (has('"')) {
skip();
emitToken('string-literal');
} else {
throw 'unclosed string literal';
}
}There are a couple of new lexer methods used here. Function hasOtherwise checks if there is a next character and it does not match the target. Function skip doesn't include the current character in the token but advances past it to the next character.
Multiple Tokens
These token-recognizing machines have so far been discussed in isolation. To build a complete lexer, the recognizers for all the different kinds of tokens must be glued together into a lexer that emits multiple types of tokens. Some developers join them manually, while others use automated tools. Explore multi-token lexers built by hand in the following exercises.
The list of tokens produced by the lexer is passed along to the next stage of translation: parsing.