Subtype Polymorphism
We've just seen how parametric polymorphism makes code reusable by leaving one or more types blank and letting the compiler fill in those blanks when it sees how the reusable code is used. With parametric polymorphism, the author of the reusable code doesn't know the types that will be dropped in the blanks, but the compiler does.
Subtype polymorphism also makes code reusable. We make code subtype polymorphic by writing it in terms of a supertype. The compiler generates a single version of the code that works with values of any type in the supertype's hierarchy. With subtype polymorphism, the author of the polymorphic code doesn't know the exact subtypes it is applied to, nor does the compiler. It only knows about the supertype.
While both polymorphisms allow a single abstraction to serve many types, parametric polymorphism has the potential to produce faster executables since the compiler knows the types. So why do we need both? Maybe we don't. Perhaps subtype polymorphism is just a legacy of the past before we invented a better way to make code reusable? After all, both Java and C++ started off with just subtype polymorphism but later gained parametric polymorphism. Rust is a newer language whose standard library employs parametric polymorphism far more frequently than subtype polymorphism.
This is an important question. However, we'll be better positioned to answer it if we first ask a preliminary question: how does the correct version of a method get called in subtype polymorphism if the compiler knows only the supertype? In other words, how does this universal print method call the right toString on a vanilla Object?
void print(Object object) {
System.out.print(object.toString());
}void print(Object object) {
System.out.print(object.toString());
}Let's find out how the right method gets called.
Manual Dynamic Dispatch
When C++ broke onto the programming scene in the 1990s, not everyone saw an object-oriented programming revolution on the horizon. One of the scoffers was computer graphics researcher Jim Blinn. At the time, Blinn wrote a column for a technical publication on computer graphics. In his column, he dismissed a key feature of C++: subtype polymorphism. He claimed to have been using it in Fortran for years and offered this “versatile” shape-drawing routine as a demonstration:
struct shape
int type
...
draw(shape)
if shape.type == 0
drawCircle(shape)
else if shape.type == 1
drawSquare(shape)
else if shape.type == 2
drawPolygon(shape) struct shape
int type
...
draw(shape)
if shape.type == 0
drawCircle(shape)
else if shape.type == 1
drawSquare(shape)
else if shape.type == 2
drawPolygon(shape) The routine has been translated from Blinn's Fortran to pseudocode. The subroutine draw draws any of three different kinds of shapes thrown at it by examining the shape's type tag and calling a shape-specific helper function. Its versatility makes it polymorphic.
The notion of deciding at runtime what routine to call for an object is dynamic dispatch. It's dynamic because the function doesn't know what sort of shape it is being asked to draw until runtime, when it examines its type tag. It's dispatch because control is being handed off to a different routine. In this case, the dynamic dispatch is manual because the programmer wrote the code to query the type tag and dispatch the appropriate helper function.
If Blinn's example is how dynamic dispatch was actually implemented, then C++ would have been rejected by the programming community. Why? For a couple of reasons:
-
The
drawroutine is full of conditional statements. You may have learned in your systems courses that conditional statements cause hiccups in the execution pipeline. The processor wants to get started on the next instruction before finishing the first, but it can't tell what instruction is next if there's a conditional. Overall performance is degraded by conditionals. -
Every time we add a new type to our hierarchy, we have to go back to the
drawroutine and update it. This routine is supposed to be high-level, able to work with any type. In reality, it is not reusable. It is omniscient, having to know every single type in the hierarchy. Maintaining that omniscience is a burden.
Thankfully, dynamic dispatch is implemented differently.
Automatic Dynamic Dispatch
Stroustrup made dynamic dispatch in C++ cheap and automatic by recording a catalog of methods for each class of a polymorphic hierarchy. He called this catalog a virtual table or vtable. Let's examine how vtables work using the following class hierarchy, courtesy of Stroustrup himself:
class A {
public:
virtual void f();
virtual void g(int);
virtual void h(double);
void i();
int a;
};
class B : public A {
public:
void g(int);
virtual void m(B*);
int b;
};
class C : public B {
public:
void h(double);
virtual void n(C*);
int c;
}class A {
public:
virtual void f();
virtual void g(int);
virtual void h(double);
void i();
int a;
};
class B : public A {
public:
void g(int);
virtual void m(B*);
int b;
};
class C : public B {
public:
void h(double);
virtual void n(C*);
int c;
}The A class has three virtual methods. Recall that virtual methods are ones that can be called across a hierarchy. If we call a virtual method on a pointer or a reference to a supertype, we'll actual be calling the subtype method.
The code for all methods is stored in the code segment of the process's memory. The vtable for A is a directory that records the locations of just the three virtual methods, and it looks something like this:
| Index | Function | Address |
|---|---|---|
| 0 | f |
&A::f |
| 1 | g |
&A::g |
| 2 | h |
&A::h |
The vtable itself is stored exactly once in static memory, not per class instance. Note that method i gets no entry because it is not virtual and does not need to be looked up at runtime.
The vtable for class B looks like this:
| Index | Function | Address |
|---|---|---|
| 0 | f |
&A::f |
| 1 | g |
&B::g |
| 2 | h |
&A::h |
| 3 | m |
&B::m |
Class B overrides g and adds m, so only those entries point to code for B. The entries for f and h just point to the code inherited from its superclass A. That means if we call f on a B instance, we will jump to the code for A::f, which is exactly right.
The vtable for class C looks like this:
| Index | Function | Address |
|---|---|---|
| 0 | f |
&A::f |
| 1 | g |
&B::g |
| 2 | h |
&C::h |
| 3 | m |
&B::m |
| 4 | n |
&C::n |
These vtable directories connect a class to its method definitions. Now we must tie instances of these classes to their vtables. Each instance of A, B, and C has an implicit instance variable that points to its class's vtable. This instance variable is the virtual pointer, which we'll abbreviate to vptr.
Consider this main function, which creates three objects on the stack:
int main() {
A o;
B p;
C q;
return 0;
}int main() {
A o;
B p;
C q;
return 0;
}An instance of A is laid out like this in memory, housing the virtual pointer and the int state declared in the class definition:
| vptr to A's vtable |
a |
An instance of B is laid out like this in memory, housing its own virtual pointer and state plus the inherited state:
| vptr to B's vtable |
a |
b |
An instance of C is laid out like this in memory:
| vptr to C's vtable |
a |
b |
c |
At the end of the main function, this is what the process's memory looks like:
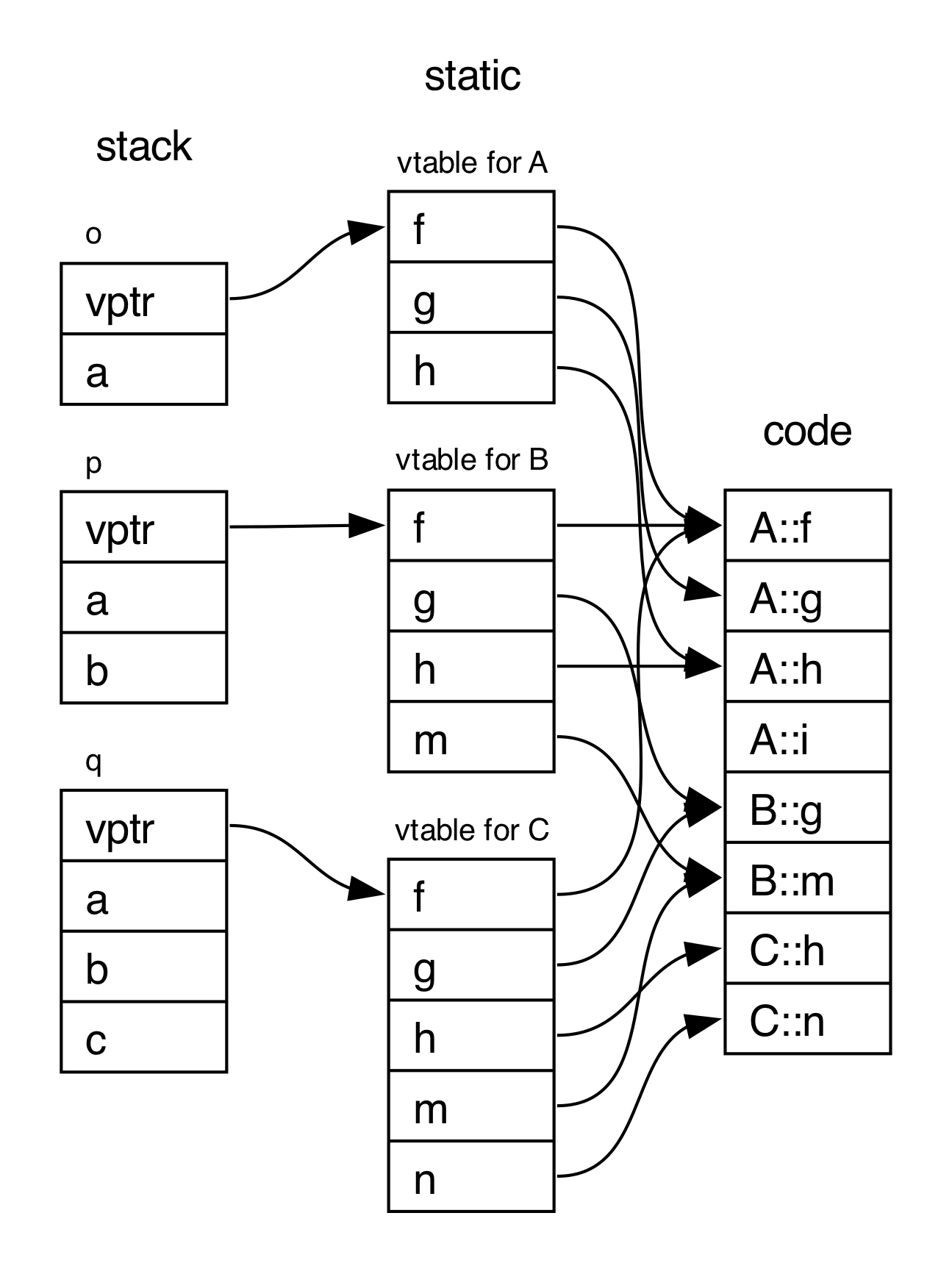
Now, suppose we have a polymorphic function process_any that takes in a pointer to A, but someone passes in an instance of C:
void process_any(A* p) {
p->g(11);
}
int main() {
C q;
process_any(&q);
return 0;
}void process_any(A* p) {
p->g(11);
}
int main() {
C q;
process_any(&q);
return 0;
}This chain of logic must occur inside of process_any to dispatch to the correct definition of g:
-
We must retrieve the vptr of
p, which points to the vtable associated with the object's real class—not just the supertype that the compiler sees. -
In the vtable pointed to by
p->vptr, we must look up the address of the code forg, which has index 1. The vtable yields the address ofB::g. -
We must call
B::gwith both the receiver object and 11 as parameters.
This chain can be reduced to a single dense statement full of memory lookups and an ugly function call:
(*(*p->vptr)[1])(p, 11);(*(*p->vptr)[1])(p, 11);
Thank goodness that we don't actually write this ourselves. The compiler inserts this code on our behalf. Despite being ugly, this implementation of dynamic dispatch is significantly better than Blinn's. No conditionals are needed. The call uses the object itself to figure out what method to run, so the caller doesn't need to be omniscient.
C++ isn't the only language to use vtables. Consider this statement from the Java Virtual Machine specification:
The Java Virtual Machine does not mandate any particular internal structure for objects.
In some of Oracle's implementations of the Java Virtual Machine, a reference to a class instance is a pointer to a handle that is itself a pair of pointers: one to a table containing the methods of the object and a pointer to the Class object that represents the type of the object, and the other to the memory allocated from the heap for the object data.
Is dynamic dispatch free? No, because there are two pointers that need be dereferenced per virtual method call at runtime. Will these memory reads be fast? Probably. The vtables will likely be stored in cache if they are frequently accessed. They are small and there's only one per class, not one per instance.
If we call a non-virtual method, then the compiler figures out at compile time what function in the code section to jump to. This is static dispatch. It is faster than dynamic dispatch. If a class has no virtual methods whatsoever, then it won't have a vptr and all method calls will be statically dispatched.
A compiler that implements parametric polymorphism through monomorphization knows the types of the polymorphic code and will therefore be able to dispatch method calls statically. This gives monomorphization a slight performance advantage over subtype polymorphism. It's also faster than parametric polymorphism through erasure, which is ultimately just subtype polymorphism.
Now that we've seen how dynamic dispatch is implemented, we return to the question of whether we need both polymorphisms in modern programming languages. Parametric polymorphism serves one particular type T, while subtype polymorphism serves a whole hierarchy of types rooted on the supertype. When we have a homogeneous collection, like a list of int, we will benefit from the fast static dispatch of parametric polymorphism. But if we have a heterogeneous collection, like a list of Shape or Enemy, we won't have a single type to drop in the blank of a generic abstraction. The elements will be scattered across a type hierarchy, so we need the more versatile dynamic dispatch of subtype polymorphism.
Because programmers have diverse needs and goals, languages continue to support both polymorphisms.