Syntax and Semantics
We now pivot from motivating the study of programming languages to actually inventing a new one. Suppose you are walking down the sidewalk and see a piece of paper sailing in the wind. The paper lands at your feet, and you find these marks printed on it:

Probably you will need to scroll horizontally to see all the marks.
You suspect this paper is a secret message and attempt to decode it. First you make the following observations:
- There are two kinds of black marks: 1-unit squares and rectangles that are three times as wide as the squares.
- Between many of the black marks, there are small 1-unit gaps.
- There are several medium 3-unit gaps.
- There is one large 7-unit gap.
Given our knowledge of how many languages work, we conclude that each sequence of black marks separated by 1-unit gaps is a letter. The letters are separated from one another by a 3-unit gap. These form words, which are themselves separated by a 7-unit gap.
The smallest parts of this language are the two kinds of black marks, but we don't attach much significance to individual marks. In a human or programming language, the smallest parts are characters. These also don't have much significance—not until they are formed into words. In a program, the individual characters form tokens, like $rate, ~, <=, ++, class, !=, ;, while, ||, }, framesPerSecond, and TAU.
When we make conclusions about how the black marks assemble into longer forms, we describe the syntax of the language. The syntax of a human language describes how words and punctuation form sentences. The syntax of a programming language describes how tokens may be arranged into valid programs. Knowing the syntax of a language is important, but the rules by themselves do not help us understand what is being communicated. To understand a language, we must also know what the arrangement of words or tokens means. The meaning behind a language's outward form is its semantics.
An exclamation mark's semantics are that a sentence has extra energy. Its syntax is a line and dot placed at the end of the sentence. The syntactic form could easily have been something else, but the semantic meaning addresses a core need in communication.
The marks on the paper do not appear to follow any syntax or semantics that we know. However, we flip the paper over and find this handy tree showing how to translate the sequence of short and long marks into letters:
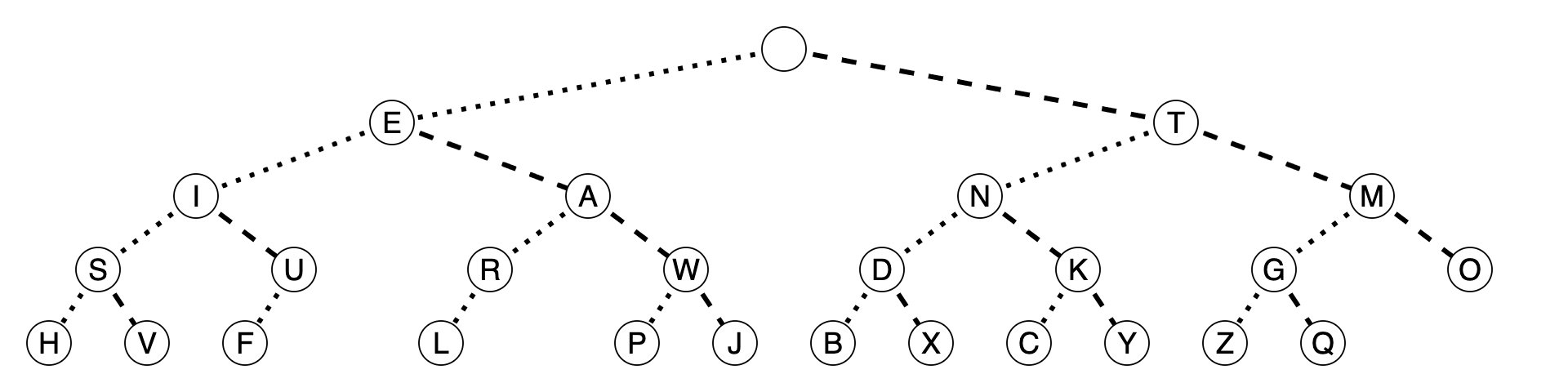
We translate each token of the message into an English letter by descending left when we see a 1-unit square and descending right when we see a 3-unit rectangle. Altogether, the letters form an English phrase whose semantics we know.
The black mark language is better known as Morse code, as you may have guessed. Likely you don't have any preconceived notions about what dot-dash-dot-dot means. But once we translate the marks into letters, we can apply the semantics of English to interpret the message.
You likely do have preconceived notions about what -x means in source code. Surely it means “negative x”. However, we can't be truly certain without knowing the semantics of the program. For example, in the following C++ program, what is negative x if x is the string stressed? Predict the output of the program, and then run it.
The semantics of code aren't always what we expect. C++ allows the - operator to be overloaded for classes, so we can't determine the meaning of -x without first knowing the type of x. Variable x is declared as a string, and - has been defined to reverse the string using a special constructor that is passed the reverse iterators rbegin and rend.
As we continue our investigation of programming languages, you'll want to view syntactic form and semantic meaning as two independent but interrelated dimensions of a language. People who think and write about programming languages organize their thoughts along these two dimensions. Developers who write software that interprets code break their algorithms into these two stages of concerns. They first use the syntax of the language to chunk tokens into established grammatical forms. Then they translate the forms into semantic representations like assignment statements, arithmetic operations, and function calls.