Lecture: Settle, Part 2
Dear students:
Last week we started building an interpreter for Settle programs. In particular, we lexed a Settle program into a list of tokens. Today we continue building that interpreter: we're going to turn a Settle program into a tree. We're not going to write every single piece of the interpreter. Instead we'll implement a vertical slice. You'll see a chunk of each layer of milestones 1 and 2 in your project.
Model Classes
Recall our example Settle program from last week:
coverings = {fur feathers scales}
coverings = coverings + {tshirt armor}
print(coverings)
print(size(coverings))coverings = {fur feathers scales}
coverings = coverings + {tshirt armor}
print(coverings)
print(size(coverings))This is the program's tree representation:
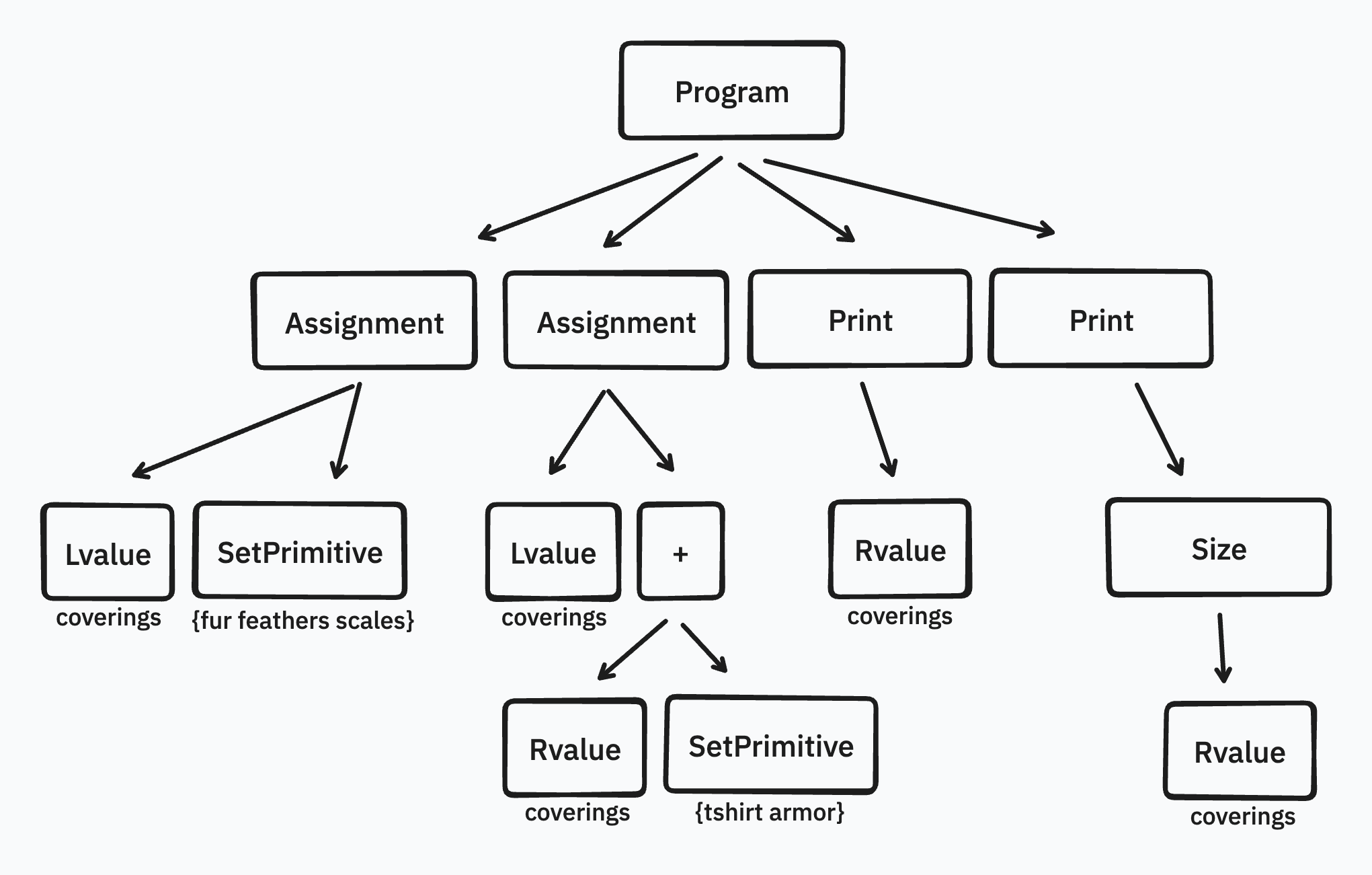
The abstract syntax tree is made up of nodes. Those nodes will be instances of a class hierarchy of program parts. These are the parts that I can think of at the moment:
-
SetPrimitive -
IntPrimitive -
Block -
Print -
Size -
Assignment -
Union -
Intersect -
Remove -
Lvalue -
Rvalue
Modeling these node types is fairly mindless work. We make a bunch of classes like this one for SetPrimitive:
module Ast
class SetPrimitive
attr_reader :members
def initialize(members)
@members = members
end
end
endmodule Ast
class SetPrimitive
attr_reader :members
def initialize(members)
@members = members
end
end
endThe attr_reader defines a getter method the members instance variable. If we don't need a getter, we don't need attr_reader.
Binary operators are only slightly more complex. With a neighbor, define Union. Here's my solution:
class Union
attr_reader :left, :right
def initialize(left, right)
@left = left
@right = right
end
endclass Union
attr_reader :left, :right
def initialize(left, right)
@left = left
@right = right
end
endWhat can you say about the types of left and right? Not much. They could be set primitives, or they could be results from some set operation, or they could be invalid node types, like an integer primitive. In Settle, we allow bad trees to be formed. In C, we do not. That's because C has a static type system, but Settle does not. We'll talk more about that next week.
Grammar
We know the pieces of Settle. We must also know how the pieces are assembled into structures. To describe the structure of a language, we use a grammar.
Programming language grammars start with a rule that describes an entire program. The starting rule often looks like this:
program = statement* EOFprogram = statement* EOF
Which of these is a terminal? Which is a non-terminal? Each non-terminal must have its own rules or productions describing its possible structures. The example program shows print statements and assignment statements, so statement might have these productions:
statement = IDENTIFIER EQUALS level0
| PRINT LEFT_PARENTHESIS level0 RIGHT_PARENTHESIS statement = IDENTIFIER EQUALS level0
| PRINT LEFT_PARENTHESIS level0 RIGHT_PARENTHESIS These productions introduce a new non-terminal: level0. Any non-terminal that starts with level describes an expression, something that produces a value. An expression can be a literal or an operation like union, intersect, remove, and xor. Each level has a precedence. Let's arrange them in what I like to think of as the Ladder of Predecence. At the bottom is levelN, with the highest precedence, which has these productions:
levelN = LEFT_CURLY IDENTIFIER* RIGHT_CURLY
| SIZE LEFT_PARENTHESIS level0 RIGHT_PARENTHESIS
| IDENTIFIERlevelN = LEFT_CURLY IDENTIFIER* RIGHT_CURLY
| SIZE LEFT_PARENTHESIS level0 RIGHT_PARENTHESIS
| IDENTIFIERSet literals, size calls, and variable lookups are all units.
The next rung up has the second highest precedence. Let's say that intersection (%) occupies this level. What is the structure of one of these expressions? We might write this as our first draft:
level1 = levelN % levelN
| levelNlevel1 = levelN % levelN
| levelNThese productions don't quite describes the structures we want to express. What if we want to intersect three sets? Something like a % b % c? That's not legal currently. We fix the problem by allowing rules to be recursive.
In tree form, what should a % b % c look like? If we want a and b to be intersected first, the tree should look this:
%
/ \
% c
/ \
a b% / \ % c / \ a b
This picture shows that we need to allow recursion in the left operand:
level1 = level1 % levelN
| level1 ^ levelN
| levelNlevel1 = level1 % levelN
| level1 ^ levelN
| levelNIf we allow both operands to be recursive, then we'd have an ambiguity in our grammar. We could interpret the expression as either (a % b) % c or a % (b % c). Ambiguities aren't good. Different compilers will produce different trees.
The rule for level0 has a similar structure, but it sits atop the level1 expressions:
level0 = level0 + level1
| level0 - level1
| level1level0 = level0 + level1
| level0 - level1
| level1On a ladder, we drop from one rung only to the one right below. We follow the same principle in our grammar. The productions either stay at their level or drop one level below to a higher precedence level. We generally don't climb back up, because that would allow a lower precedence operation to sneak in under a higher-precedence operation. However, we do make rare exceptions when there's a boundary that resets the precedence. For example, levelN can jump back up to level0 inside parentheses.
This grammar might seem like just an inconsequential thinking exercise. Where's the code? But it's important. This is how programming languages are specified. Grammars are included in a language's technical documentation. This grammar very nearly writes the parsing code for us.
Parser
We write a grammar to inform our implementation of a recursive descent parser, just as state machines informed our implementation of a lexer. Each non-terminal of a grammar becomes a method in our parser. I like to break off implementing a parser one rung at a time, starting at the bottom. Before we parse levelN, let's have a look at our utility methods:
- a constructor that receives the tokens
-
has(type), which looks to see if the next token has a particular type -
advance, which moves ahead to the next token -
parse, which runs through all the tokens and recursively builds a tree
Once we've implemented these universal parsing methods, then we are ready to implement the methods for our particular grammar's non-terminals. One production of levelN translates into this:
class Parser
# ...
def levelN
if has(:left_curly)
advance # eat {
ids = []
while has(:identifier)
id = advance
ids.push(id.text)
end
if !has(:right_curly)
raise "Unterminated set literal"
end
advance # eat }
Ast::SetPrimitive.new(ids)
else
raise "Unexpected token: #{@tokens[@i]}"
end
end
endclass Parser
# ...
def levelN
if has(:left_curly)
advance # eat {
ids = []
while has(:identifier)
id = advance
ids.push(id.text)
end
if !has(:right_curly)
raise "Unterminated set literal"
end
advance # eat }
Ast::SetPrimitive.new(ids)
else
raise "Unexpected token: #{@tokens[@i]}"
end
end
endWhile we're testing, we'll have the parse method call whatever method we're testing. Eventually we'll have it point at our starting non-terminal. At this point, our parser can only turn set literals into trees.
def level1
left = level1
if has(:percent)
advance
right = levelN
left = Ast::Intersect.new(left, right)
end
left
enddef level1
left = level1
if has(:percent)
advance
right = levelN
left = Ast::Intersect.new(left, right)
end
left
endThis code has a problem. The very first statement is a recursive call to the method we are trying to write. Our program will quickly reach a stack overflow. To fix this, we fold the recursion into a loop:
def level1
left = levelN
while has(:percent)
advance
right = levelN
left = Ast::Intersect.new(left, right)
end
left
enddef level1
left = levelN
while has(:percent)
advance
right = levelN
left = Ast::Intersect.new(left, right)
end
left
endWe would craft level0, statement, and program in a similar manner.
TODO
Here's your list of things to do before we meet next:
See you next time.
Sincerely,

P.S. It's time for a haiku!
illness
But there's no cause for alarm
It's non-terminal